Production RAG Evaluator
View SourceSample your RAG responses in production, score them across four dimensions, and find out when your system is making things up. ML classifiers handle the obvious cases; LLM reasoners debate the hard ones.
What AgentField handles
Building this yourself means wiring up message queues, service discovery, load balancing, retry logic, and observability. That's weeks of infrastructure work. AgentField gives you orchestration, parallel execution, cross-agent calls, and execution traces out of the box. You write the evaluation logic.
Your RAG system is in production. Users are asking questions. Sometimes it makes things up. How do you know?
This evaluator runs alongside your system, sampling a fraction of responses and scoring them. Fast ML classifiers handle the easy cases (about 70%). For the tricky ones, multiple LLM "reasoners" debate whether the response is faithful to the source material.
You get:
- A Next.js dashboard to see what's failing and why
- Four evaluation metrics: faithfulness, relevance, hallucination detection, constitutional compliance
- REST endpoints so you can build your own UI or pipe data into Grafana
- The source code to add your own evaluators
# Preview: Full evaluation in one call
from agentfield import Agent, AIConfig, AgentRouter
app = Agent(node_id="rag-evaluation")
router = AgentRouter()
@router.reasoner()
async def evaluate(question: str, context: str, response: str):
faithfulness, relevance, hallucination, constitutional = await asyncio.gather(
router.app.call("rag-evaluation.evaluate_faithfulness", ...),
router.app.call("rag-evaluation.evaluate_relevance", ...),
router.app.call("rag-evaluation.evaluate_hallucination", ...),
router.app.call("rag-evaluation.evaluate_constitutional", ...)
)
return {"faithfulness": faithfulness, "relevance": relevance, ...}Expected output:
{
"overall_score": 0.87,
"faithfulness": {"score": 0.92, "claims_verified": 3, "unfaithful_claims": []},
"relevance": {"score": 0.85, "addresses_question": true},
"hallucination": {"detected": false, "method": "ml_classifier"},
"constitutional": {"score": 0.90, "violations": []}
}Quick Start
See the README for setup instructions (Docker or local development).
Running This in Production
You probably don't want to evaluate every response. At 10,000 requests/day, that's expensive and slow.
Sampling Strategy
Evaluate a sample instead. Under heavy load, drop to 1% sampling. For enterprise customers, bump it to 10%. If your RAG returns a low-confidence answer, always evaluate it.
Collecting Data Over Time
The REST API returns structured JSON. Pipe it into Postgres, Datadog, whatever. Track how faithfulness scores trend week-over-week. Find which document sources produce the most hallucinations. Watch whether your P95 latency is creeping up.
Building Your Own Dashboard
The included Next.js UI shows what's possible. The REST API gives you everything you need to build React/Vue dashboards, integrate with Grafana, or set up Slack alerts when metrics degrade.
Adding Your Own Evaluators
The four built-in metrics are a starting point. Fork the repo and add what you need.
If you're doing healthcare RAG, add a medical accuracy checker that validates drug names and dosages against a formulary. Legal RAG? Add citation verification that checks if case law references actually exist. Developer tools? Maybe an evaluator that runs code snippets and checks if they compile.
How It Works
AgentField agents are FastAPI-like servers. Each reasoner is an async function:
from agentfield import Agent, AIConfig
from reasoners import router
app = Agent(
node_id="rag-evaluation",
version="1.0.0",
)
app.include_router(router)
if __name__ == "__main__":
app.run(auto_port=True, host="0.0.0.0")The orchestrator runs four evaluation metrics in parallel:
@router.reasoner()
async def evaluate_rag_response(
question: str, context: str, response: str,
mode: str = "standard", domain: str = "general"
) -> EvaluationResult:
# Run all four evaluators in parallel
faithfulness, relevance, hallucination, constitutional = await asyncio.gather(
router.app.call("rag-evaluation.evaluate_faithfulness", ...),
router.app.call("rag-evaluation.evaluate_relevance", ...),
router.app.call("rag-evaluation.evaluate_hallucination", ...),
router.app.call("rag-evaluation.evaluate_constitutional", ...)
)
# Compute weighted overall score
overall = compute_overall_score(faithfulness, relevance, hallucination, constitutional)
return EvaluationResult(overall_score=overall, ...)No DAGs. No YAML. Just Python.
Evaluation Metrics
Four metrics, each with a unique multi-reasoner pattern:
| Metric | Pattern | What Happens | Avg Cost |
|---|---|---|---|
| Faithfulness | Adversarial Debate | Prosecutor attacks claims, Defender supports them, Judge decides | 4 AI calls |
| Relevance | Jury Consensus | 3 jurors vote (literal, intent, scope), Foreman synthesizes | 5 AI calls |
| Hallucination | Hybrid ML+LLM | ML handles 70% of cases, LLM handles edge cases | 0.3 AI calls |
| Constitutional | Parallel Principles | 5 principle checkers run simultaneously | 6 AI calls |
Evaluation Modes
Choose evaluation depth based on your use case:
| Mode | Evaluators | AI Calls | Cost | Use Case |
|---|---|---|---|---|
| quick | 2 | 3 | ~$0.001 | Real-time validation, FAQ |
| standard | 4 | 10-14 | ~$0.003 | Production evaluation |
| thorough | 4+ | 18+ | ~$0.008 | Medical, legal, financial audits |
Usage Options
# Call from any language, frontend, or pipeline
curl -X POST 'http://localhost:8080/api/v1/execute/rag-evaluation.evaluate_rag_response' \
-H 'Content-Type: application/json' \
-d '{
"input": {
"question": "What causes climate change?",
"context": "Climate change is primarily caused by human activities...",
"response": "The main causes are fossil fuels and deforestation...",
"mode": "quick"
}
}'import requests
class RAGEvaluator:
def __init__(self, control_plane_url: str):
self.url = control_plane_url
def evaluate(self, question: str, context: str, response: str, mode: str = "standard"):
return requests.post(
f"{self.url}/api/v1/execute/rag-evaluation.evaluate_rag_response",
json={"input": {"question": question, "context": context, "response": response, "mode": mode}}
).json()
# Usage
evaluator = RAGEvaluator("http://localhost:8080")
result = evaluator.evaluate(
question="What is the main benefit of RAG?",
context="RAG combines retrieval with generation...",
response="RAG reduces hallucinations by grounding responses."
)
print(f"Score: {result['result']['overall_score']}") # 0.94# Call individual reasoners for custom pipelines
curl -X POST 'http://localhost:8080/api/v1/execute/rag-evaluation.evaluate_faithfulness' \
-H 'Content-Type: application/json' \
-d '{
"input": {
"question": "What is RAG?",
"context": "RAG combines retrieval with generation...",
"response": "RAG is a technique that grounds LLM responses."
}
}'Each reasoner is independently callable for custom evaluation pipelines.
Advanced Patterns
Web UI
The included Next.js web interface provides real-time evaluation with detailed breakdowns.
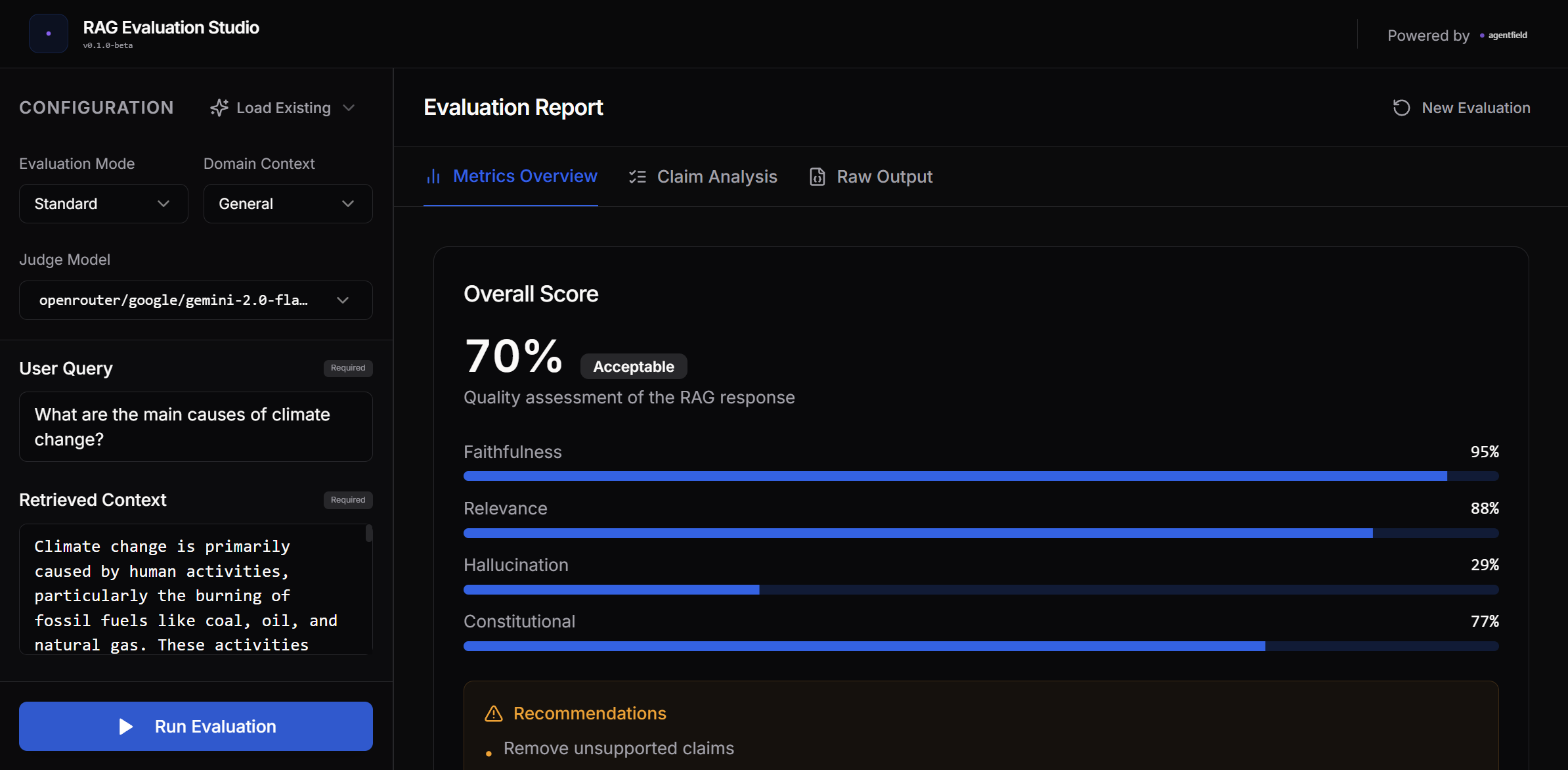
Overall evaluation score with per-metric breakdown bars
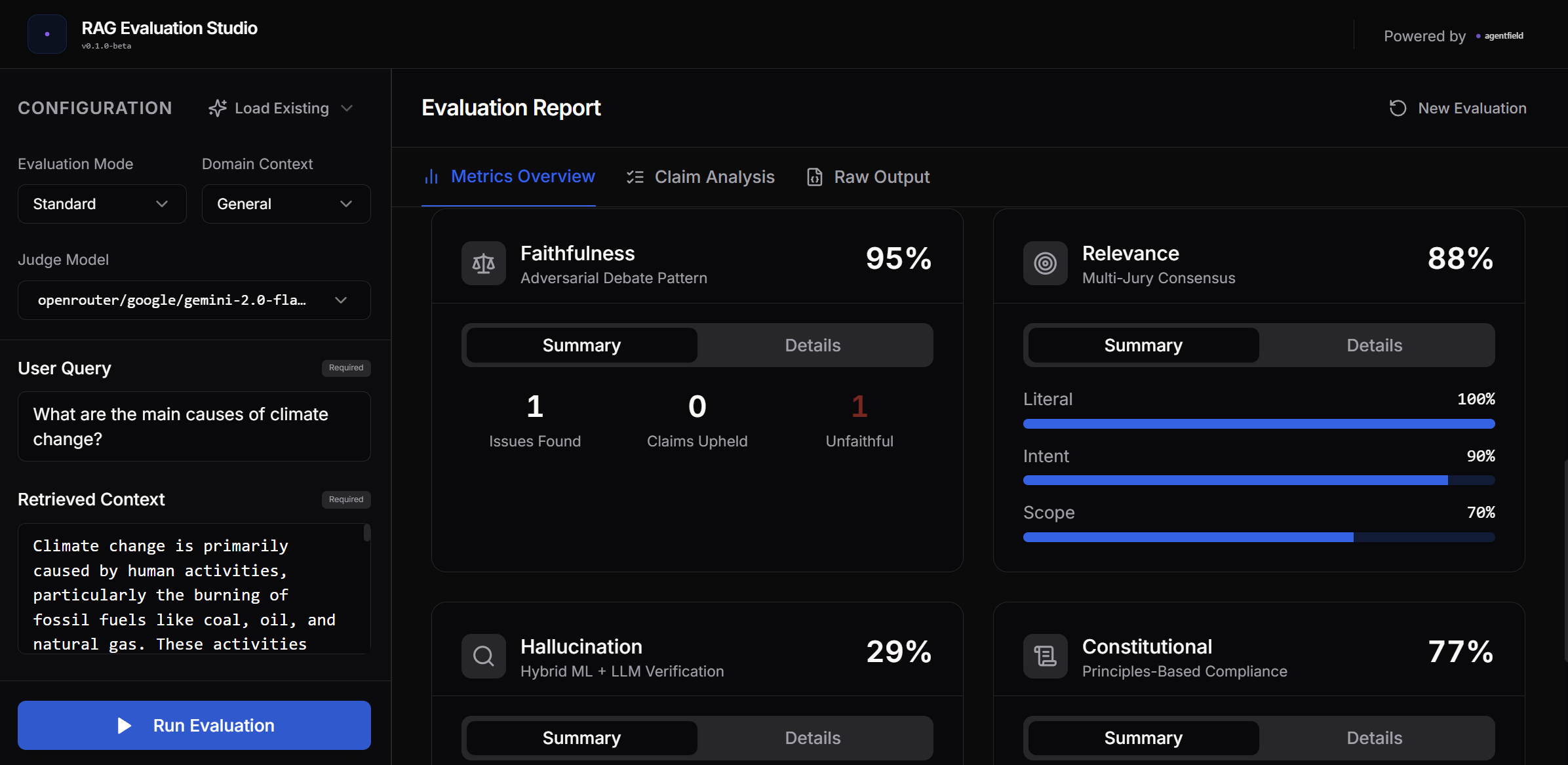
Detailed metric cards with individual scores and drill-down options
What you can do with the UI:
See every claim extracted from a response, with the "prosecutor" and "defender" arguments side by side. Switch between quick (3 API calls), standard (10-14 calls), or thorough (18+) evaluation depth. Results stream in via SSE so you can watch the evaluation happen. There are preset examples for different domains if you want to kick the tires.
Learn More
New to AgentField? Start with Agents (the server processes) and Reasoners (the AI operations).
For the API used in this example, see router.ai() for LLM calls and router.app.call() for cross-agent communication.