A useful way to think about where AI fits in software
The speed at which agent-style systems have moved from research to demos to daily use has been remarkable, even as their impact inside real business environments remains uneven.
On the surface, progress looks obvious. Models are more capable. Tools are more accessible. We see impressive demonstrations almost daily, from deep research systems to coding assistants that can scaffold entire projects. And yet, when these systems are introduced into real software environments, especially ones that already operate at scale, the outcomes often feel narrower than expected. A few use cases stand out. Many remain experimental. Most struggle to move beyond individual productivity.
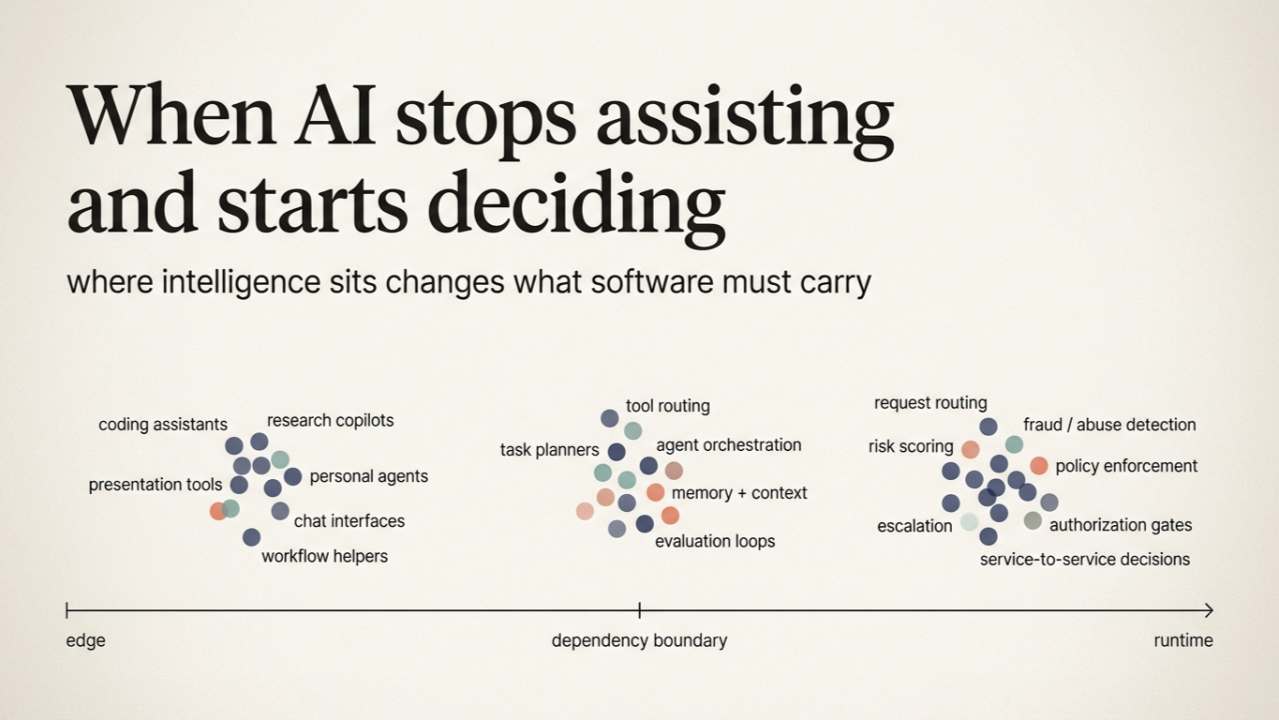
This gap is often discussed in terms of maturity, safety, or trust. Those matter, but they are not the whole story. What seems more revealing is that we are grouping very different kinds of systems under a single mental model. We talk about "AI agents" or "AI applications" as if they belong to the same category, even when they behave very differently once they leave a demo and begin interacting with real systems. The difference is not about intelligence or capability. It has more to do with where intelligence sits in the architecture and what the surrounding system expects from it. Once you look at AI through that lens, a clearer split begins to appear, and many of the outcomes we are seeing start to make more sense.
AI Systems Designed for Interaction at the Edge
A large class of current AI systems is built around interaction. These systems live close to the user. They take in loosely structured input, often through natural language, and respond in ways that remain flexible and conversational. Coding assistants, research tools, presentation generators, and personal agents fall into this category.
In interaction first systems, the person using AI interprets the output, decides what matters, corrects mistakes, and chooses what action to take next
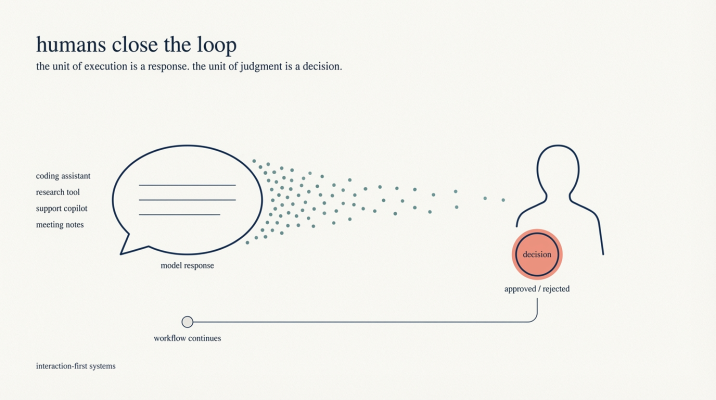
What makes these systems powerful is not just their reasoning ability, but the role the human plays around them. The person using the system interprets the output, decides what matters, corrects mistakes, and chooses what action to take next. Ambiguity is present throughout the process, but it is resolved socially rather than technically. The system can remain forgiving because a person is holding it together.
This pattern works well for a wide range of tasks. It explains why some of the most useful AI applications today center on exploration, synthesis, and individual workflows. Writing, research, and coding benefit from flexibility and iteration. When something goes wrong, the cost is usually limited, and the feedback loop is immediate.
These systems are often described as agents because they feel active and responsive. They can call tools, maintain context, and adapt to changing instructions. For an individual user, this feels like delegation. For the surrounding software environment, however, the AI is still operating at the boundary. Its outputs are suggestions, not dependencies. The responsibility for correctness, authorization, and follow-through remains with the person in the loop.
Seen this way, many current AI successes are not surprising. They are optimized for interaction, not for being depended on by other systems.
AI Systems Embedded Inside Software Runtimes
There is another class of AI systems that receives far less attention, partly because it is harder to see and partly because it does not present itself through conversation. This is the pattern I have found myself increasingly interested in.
In these systems, intelligence does not sit at the edge waiting for a human to interpret it. It is embedded inside the software itself. The AI operates within a bounded role, often at a specific decision point. It routes a request, evaluates risk, reconciles conflicting signals, classifies an event, or decides whether to escalate. These are decision points woven into the flow of software, invisible unless you know where to look. Nobody interacts with them. Other systems depend on them. What goes into the system is structured. What comes out is structured. The flexibility lives inside the decision process rather than at the interface.
In embedded systems, the AI operates within a bounded role in backends as part of software stack
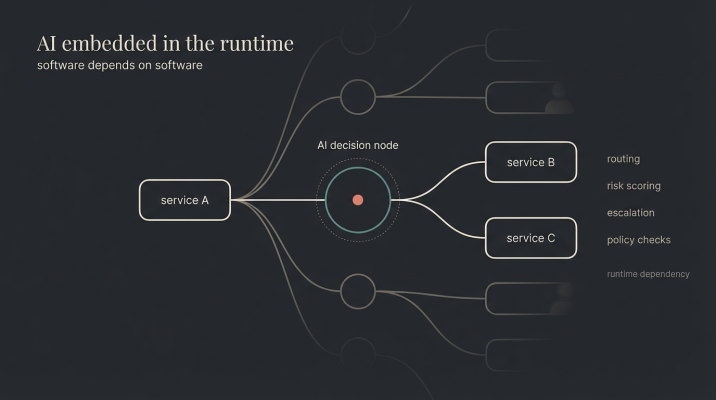
This kind of system is not designed to feel helpful or expressive. It is designed to be dependable. Other services rely on its output. Downstream processes assume it behaved correctly. There is no person standing by to smooth over ambiguity or reinterpret intent after the fact.
What makes this pattern subtle is that the intelligence involved can be just as sophisticated as anything we see in interactive systems. The difference is not reasoning power. The difference is responsibility. Once an AI system begins to act as part of a runtime, it stops being an assistant and starts behaving like software that other software depends on.
Many of the frictions people experience when moving AI into production start to look different when viewed through this lens. It helps explain why progress feels uneven, why some deployments stall after early success even when the underlying technology performs well in isolation, and why maturity in one category does not transfer cleanly to another. These systems rarely look impressive in isolation, but they shape how work actually moves through an organization.
Why Most Visible Progress Clusters Around the First Pattern
Once this distinction is on the table, another pattern becomes easier to notice.
Nearly all applications and tools sit firmly in interaction-first category being high on demo-ability
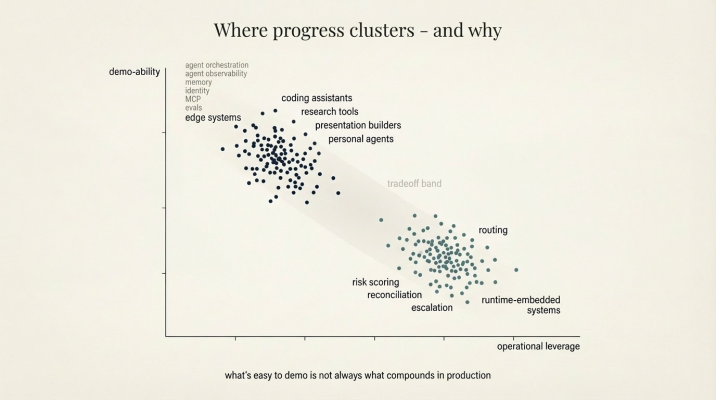
Nearly all of the AI applications that feel most mature today sit firmly in the interaction-first category. Tools for writing, research, presentation building, coding, and analysis are designed around direct human engagement. Even when they are used inside enterprises, their center of gravity remains the individual user. The interface is conversational and the feedback loop is personal. The system assumes a human will decide what to trust and what to ignore.
This is also where much of the surrounding tooling has developed. Frameworks for tool calling, context management, and orchestration have been shaped by this interaction model. Developer tools that help wire models to APIs, as well as emerging standards like Model Context Protocol, are optimized around giving a single agent access to a growing set of capabilities in a controlled way. Security, permissions, and policy discussions in this space tend to focus on what a personal agent should be allowed to touch.
None of this is accidental. Designing for a human-facing loop simplifies many hard problems. Ambiguity can remain unresolved. Errors can be corrected conversationally. The system does not need to justify itself to another system. It only needs to be useful enough for a person to keep working with it.
Where the Real Distinction Appears
The contrast surfaces something that was harder to name before. Ambiguity always exists in systems that interact with the real world. Inputs are incomplete. Signals conflict. Context changes faster than code can be updated.
The question is never whether ambiguity is present. The question is where it is allowed to live.
Edge systems support wider variance while embedded AI systems are stochastic within bounds
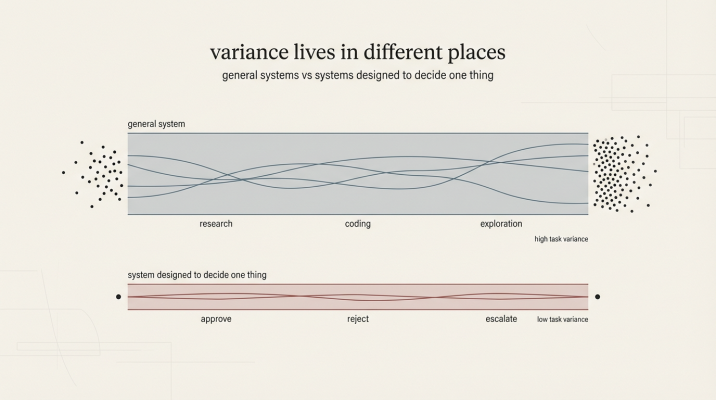
In interaction-first systems, ambiguity is pushed outward. The AI produces a response that may be partial, approximate, or situational. A human reads it, interprets it, and decides what to do next. The system remains flexible because the resolution happens outside the software boundary.
In runtime-embedded systems, ambiguity moves inward. The AI still reasons over messy signals, but it does so inside a bounded role. What enters the system is structured. What leaves the system is structured. Other software depends on that output behaving consistently enough to be acted upon.
This difference matters because the moment an AI output becomes a dependency, ambiguity changes character. What was previously tolerable becomes fragile. A suggestion can be vague. A decision cannot. When downstream systems rely on an outcome, ambiguity turns into a liability rather than a convenience.
Seen this way, many current patterns fall neatly into place. The split is not about use case or industry. It is about where uncertainty is resolved and who is expected to carry it.
Why the Requirements Change When Intelligence Moves Inward
When intelligence sits at the edge, the primary question tends to be whether the system is helpful. When intelligence becomes part of the runtime, the question shifts almost immediately. The concern becomes whether the system is safe to depend on.
Current tooling from MCP to agentic frameworks are built for personal edge systems
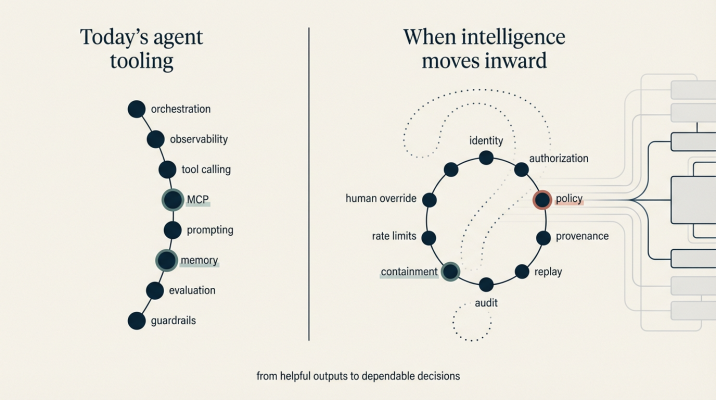
This shift does not happen because of organizational caution or regulatory pressure. It happens because software has expectations of other software. A system that consumes an AI decision implicitly assumes that someone or something was authorized to make it. It assumes the decision can be traced, revisited, and explained if needed. It assumes failures are contained rather than amplified.
Questions begin to surface naturally. Who authorized this action. What context did the system rely on. Can this decision be replayed or audited later. What happens when the system is wrong.
These are not additional features layered on top of intelligence, rather they are consequences of placing intelligence inside a dependency chain.
As soon as AI begins to act on behalf of the system rather than the user, the surrounding infrastructure has to carry responsibility that a human previously absorbed without noticing.
A Simple Way to Tell Which Pattern You Are Dealing With
There is a simple question that clarifies this distinction more reliably than most architectural diagrams. If an AI system produces a wrong outcome, who notices first.
If the answer is a person reading a response, the system is operating at the interface. The human acts as the checksum. They catch inconsistencies, correct mistakes, and decide how much to trust the output.
If the answer is the system itself, the AI is part of the runtime. Infrastructure has to play the role of checksum. It must detect anomalies, enforce boundaries, and surface issues without relying on a person to notice something feels off.
This single question cuts through much of the confusion around agents, autonomy, and production readiness. It reveals where responsibility actually sits, regardless of how the system is described.
An Invitation to Look at Systems Differently
Both patterns matter. Interaction-first systems unlock speed and creativity. Runtime-embedded systems enable delegation at scale. One does not replace the other.
What changes is responsibility. Different placements of intelligence imply different expectations of the surrounding software. The work is not choosing the right kind of AI. It is deciding where ambiguity belongs and who is expected to absorb it.
Once that question is asked clearly, many design choices become easier to reason about. The conversation shifts from tools and interfaces to architecture and responsibility. That shift alone can be enough to see familiar systems in a new light, and as AI shifts from experimentation toward becoming a dependency, having a clear way to name these differences becomes less optional and more clarifying.